The Evolution of the Inference Stack for LLMs

LLMs are not just Big Web Apps, they are Fat Microservices …
Latency is the silent killer of the AI user experience. We’ve all been there: staring at that "spinning wheel" or a blinking cursor while a model like Gemini or GPT-4o seemingly "thinks." In my years managing thousands of GPUs, we have learned that this pause isn't just a minor delay—it's the friction point where infrastructure meets the limits of physics.
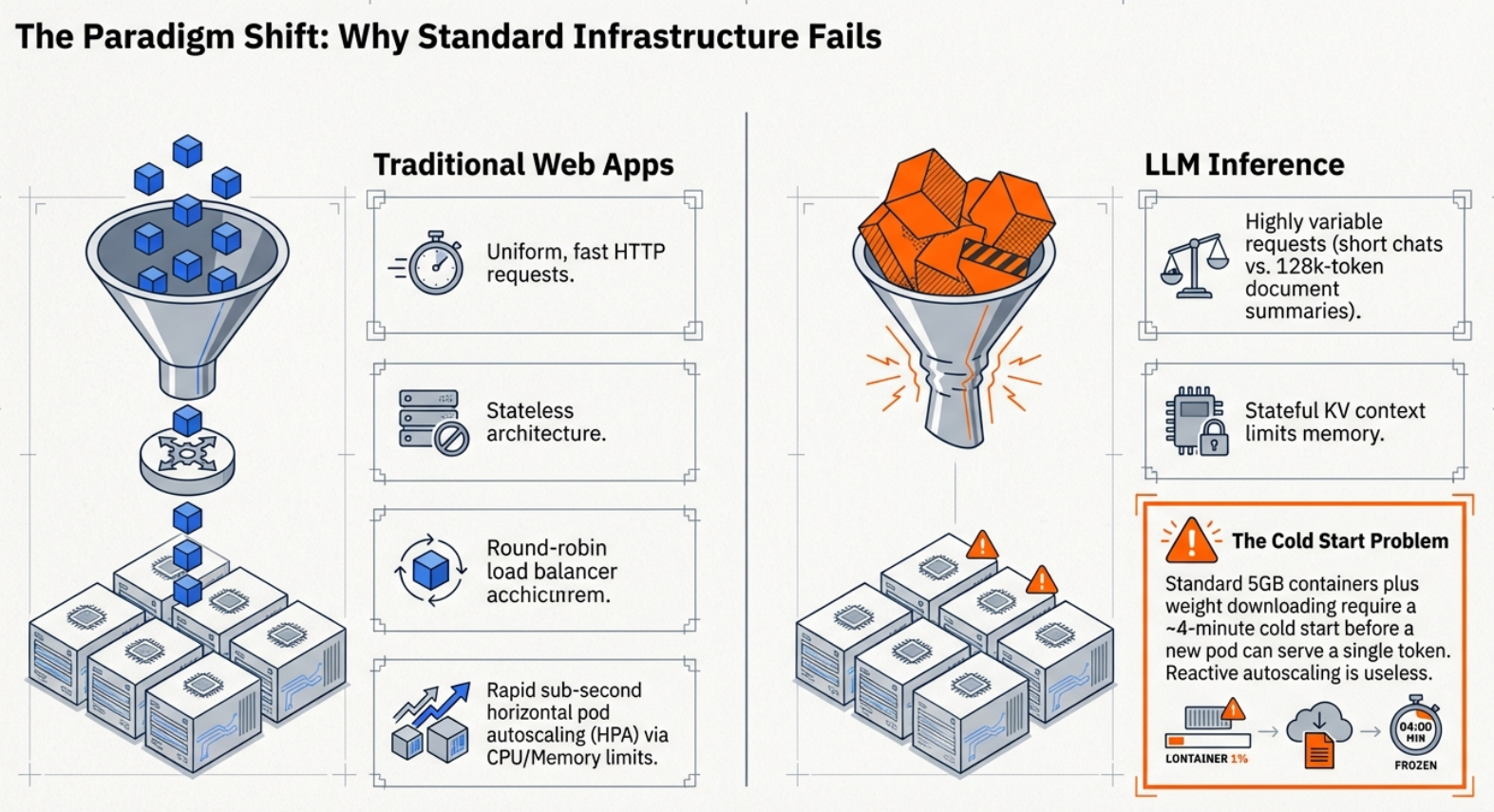
As we move through 2026, the industry has finally realized that LLMs are not just "big web apps". They are "fat microservices" that break every rule of traditional scaling. We can't just throw more RAM at a VRAM wall or rely on standard load balancing when a single request might take three seconds to "decode" token-by-token. To keep the tokens flowing, we’ve had to rewrite the entire inference stack.
Here are the five breakthroughs currently defining the frontier of large-scale LLM deployment.
1. The "Slowest Runner" Trap: Why Static Batching is Killing
Our Throughput
In the early days of LLM deployment, we relied on "Static" or "Naive" batching. We’d group requests together, pad them to the same length, and run them through the GPU. The problem? LLM inference is non-uniform. If User A asks for a haiku and User B asks for a 2,000-word essay, the system is stuck. Because tokens are generated one-by-one, the entire batch is held hostage by the longest sequence.
"This is very inefficient because we need to wait that all the sequences are finished to be decoded to provide a response to the user and all the incoming requests are idle waiting for the current batch to be decoded."
The breakthrough is Continuous Batching. Instead of waiting for the whole group to finish, the engine "re-batches" at every single iteration. As soon as a sequence generates an "end of sequence" (EOS) token, it’s ejected and a new request from the queue is swapped in immediately.
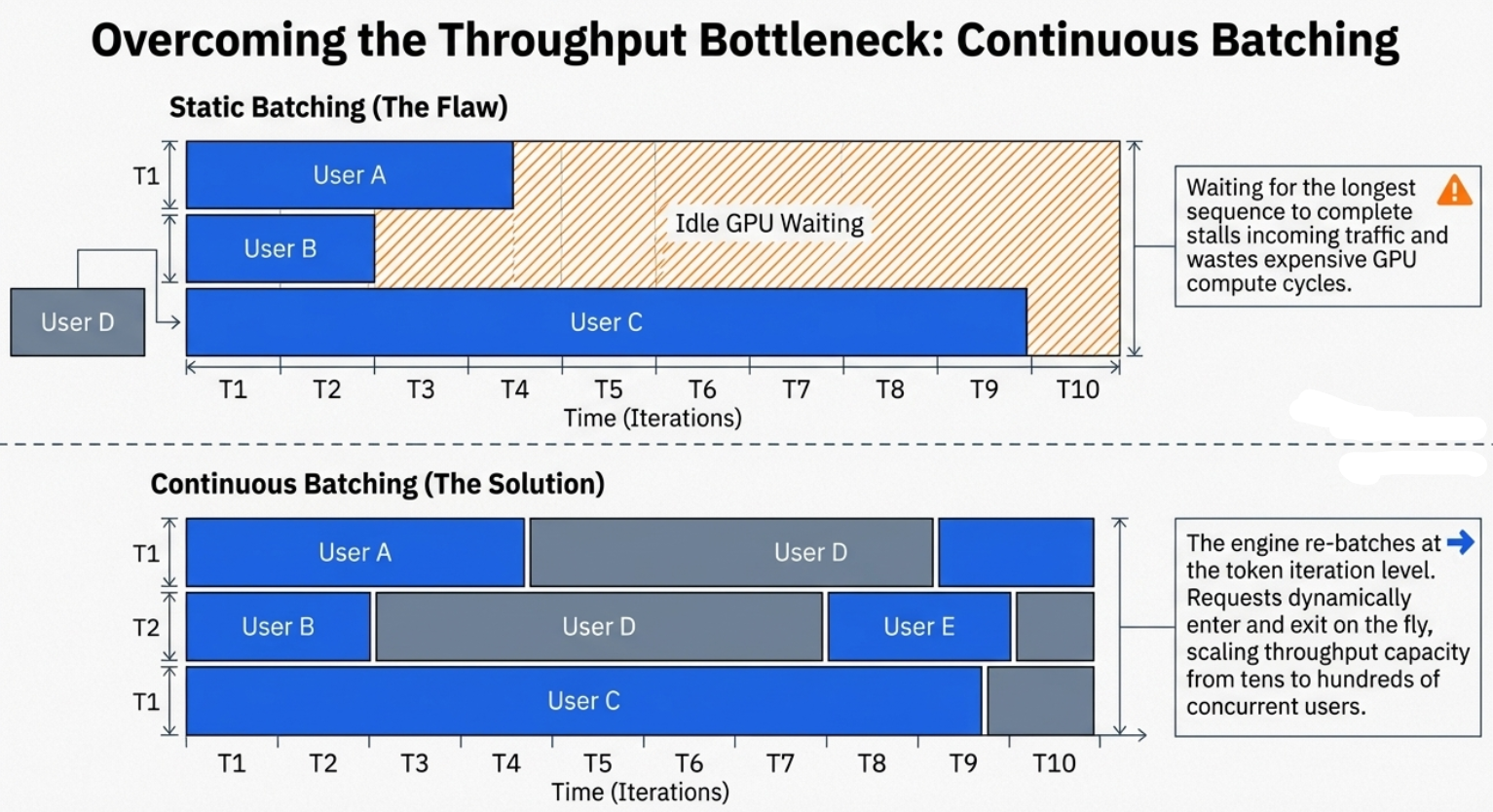
Continuous batching transforms the user experience from a "stop-and-go" traffic jam into a fluid, high-utilization stream, ensuring our expensive H100s or Blackwells are never sitting idle while a short request finishes.
2. PagedAttention: Borrowing a 1960s OS Trick to Save 60% of GPU Memory
The "VRAM wall" is the greatest bottleneck in AI. To avoid re-calculating the entire prompt for every new word, we store Key-Value (KV) vectors in a cache. Traditionally, this KV cache required large, contiguous blocks of memory. Because we couldn’t predict the length of a response, we had to over-allocate for the "worst-case scenario", leading to massive internal fragmentation.
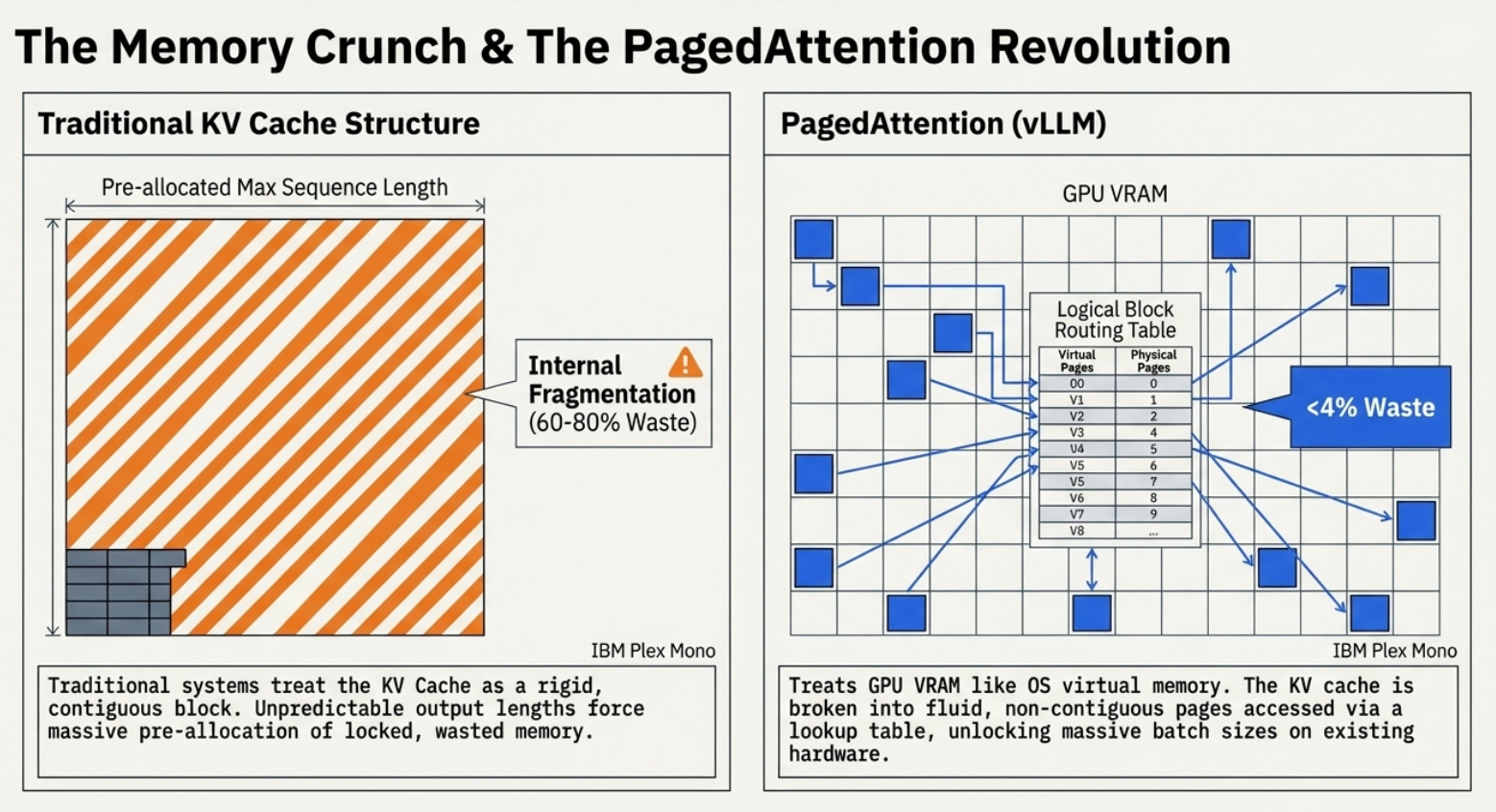
The solution, popularized by vLLM, is PagedAttention. By treating the KV cache like Virtual Memory in an operating system, we break the cache into small, non-contiguous "pages."
The Tiny Desk Analogy Think of the GPU as a tiny desk and the system RAM as a giant filing cabinet. If the "book" (the model and its cache) is too big for the desk, we waste time getting up to swap chapters from the cabinet. PagedAttention allows us to keep only the specific "pages" we need on the desk at any moment, scattered wherever they fit.
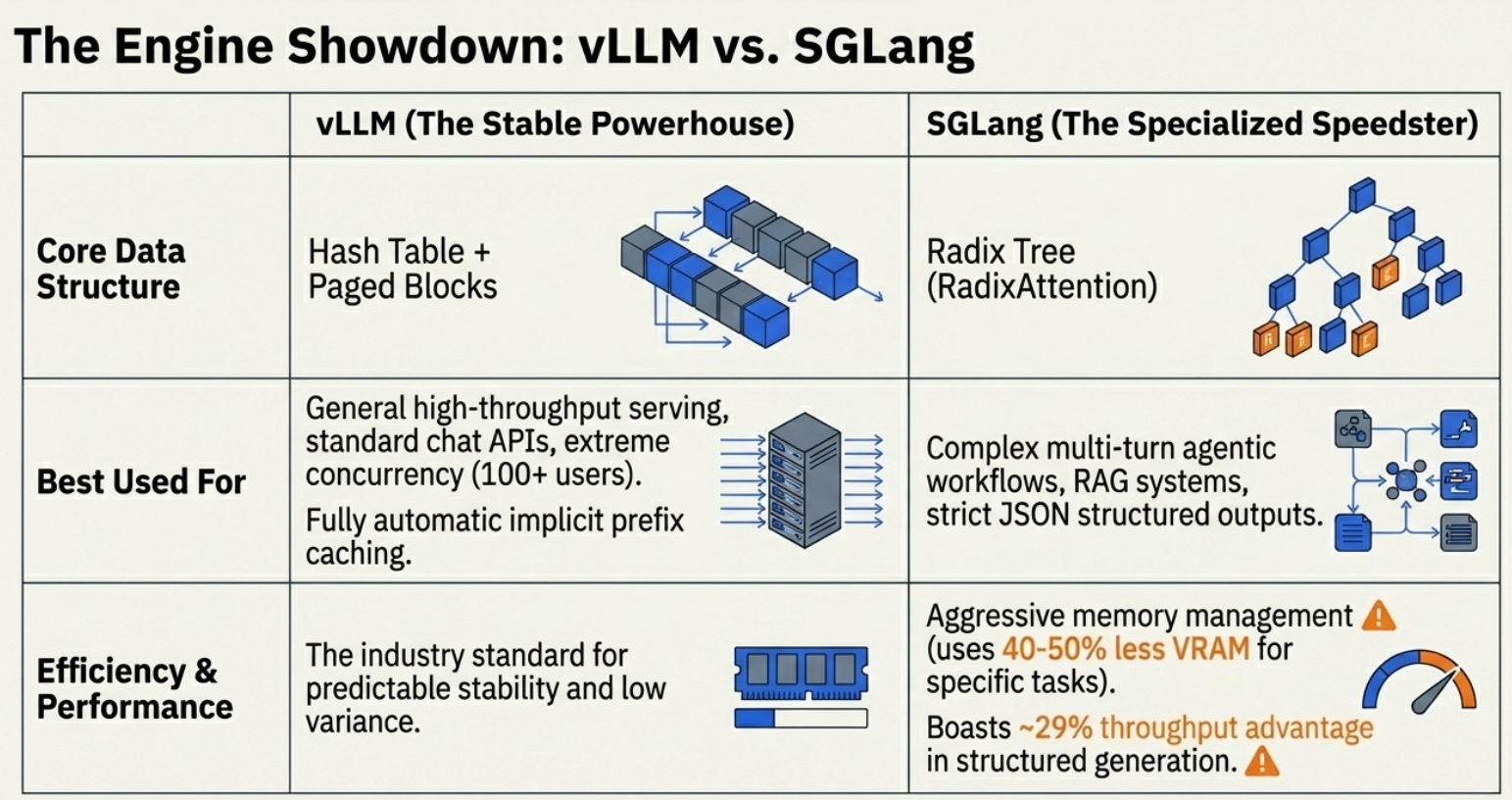
By moving from rigid blocks to fluid pages, we’ve reduced VRAM waste from 60-80% down to under 4%. While vLLM remains the industry standard, 2026 has seen the rise of SGLang. Using RadixAttention (a Radix Tree structure instead of simple hashing), SGLang offers a 29% throughput advantage in agentic workflows by "remembering" shared prefixes—like long system prompts or PDF contexts—across different user requests.
3. The Schizophrenic Nature of Inference: Prefill vs. Decoding
To optimize an LLM, we have to accept that we are essentially running two different programs inside one model. Inference is not a single "jump"; it is a two-stage process with diametrically opposed hardware constraints.
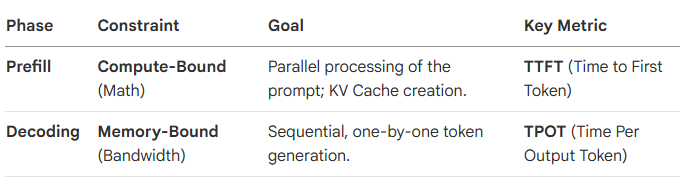
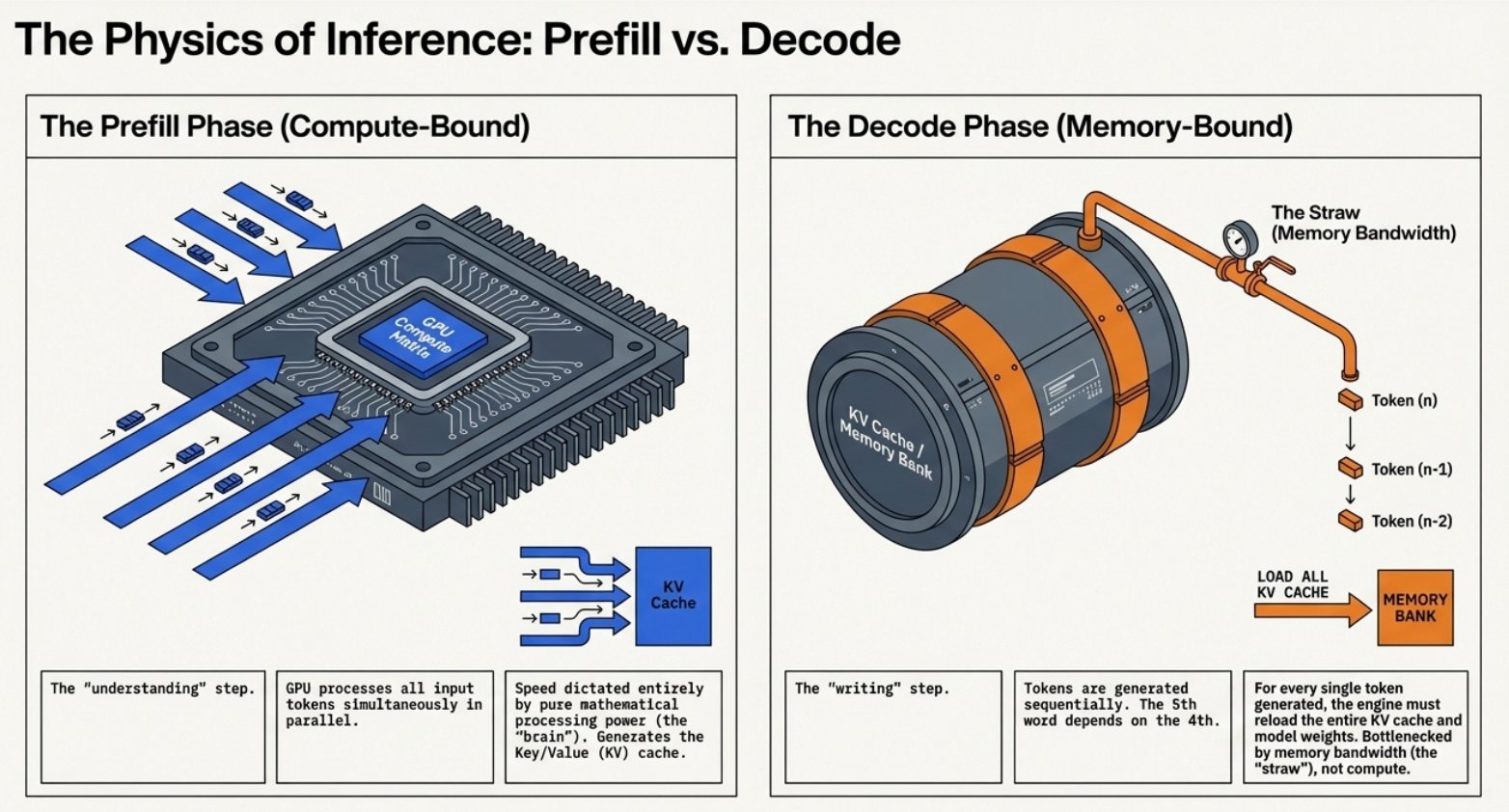
In the Prefill Phase, the GPU is a math powerhouse, parallelizing the entire input. In the Decoding Phase, the GPU is "sucking data through a straw," limited not by its "brain" (FLOPs) but by how fast it can pull the KV cache from memory. Decoupling these phases is the prerequisite for all 2026 cost-savings; we simply cannot optimize a math-heavy process and a bandwidth-heavy process using the same hardware strategy.
The realization that prefill and decoding are distinct led to Disaggregated Inference (PD Disaggregation). Instead of forcing a single GPU to be a "jack of all trades," we split the workload across specialized accelerators..
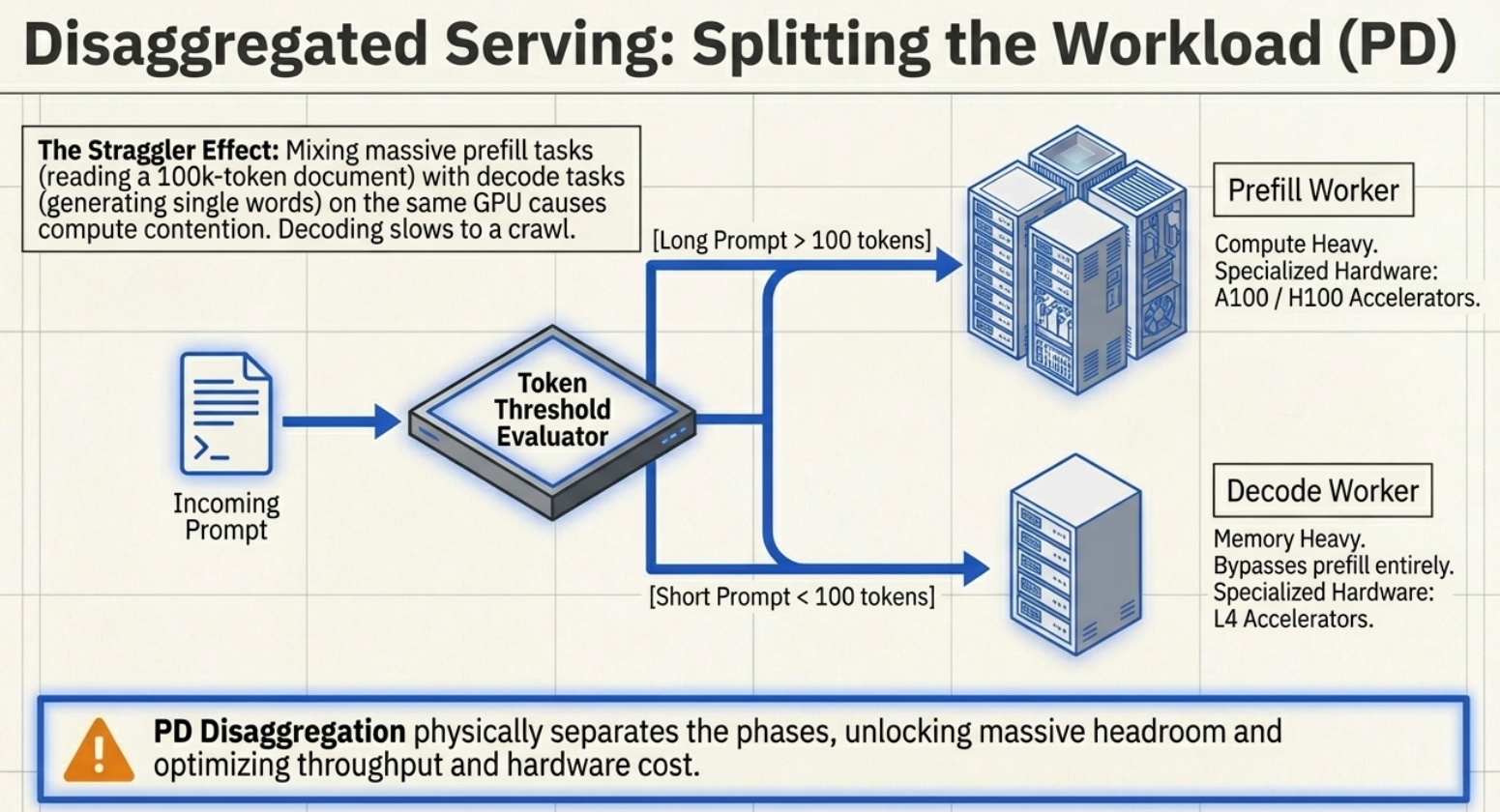
In a disaggregated setup (part of the LMD/LLM-D project), we use compute-heavy nodes (like NVIDIA H100s) for the Prefill stage. Once the KV cache is created, it is transferred via NIXL (NVIDIA Inference Xfer Library)—which enables GPU Direct peer-to-peer communication—to Decoding nodes. These decoding nodes often use more cost-effective, memory-bandwidth-optimized cards like the NVIDIA L4.
This split is crucial for large-scale inference because it prevents the "math" of a new prompt from starving the "writing" of an ongoing one. It allows us to scale prefill and decoding independently, slashing TTFT while keeping the cost per token at an all-time low.
4. The “Fat Microservice" Problem: Why Standard Kubernetes Fails LLMs
Standard Kubernetes Horizontal Pod Autoscaling (HPA) was built for lightweight web apps. It fails LLMs for three reasons: container images are massive (5GB+), model weights take minutes to download (50GB+), and GPU "warming" is painfully slow. By the time HPA spins up a new pod, our traffic spike is over.
The 2026 orchestration layer, led by the LMD (Kubernetes-native, accelerator-agnostic) stack, solves this through:
LeaderWorkerSet: A new primitive that allows a massive model to be sharded across multiple physical nodes but managed as a single unit.
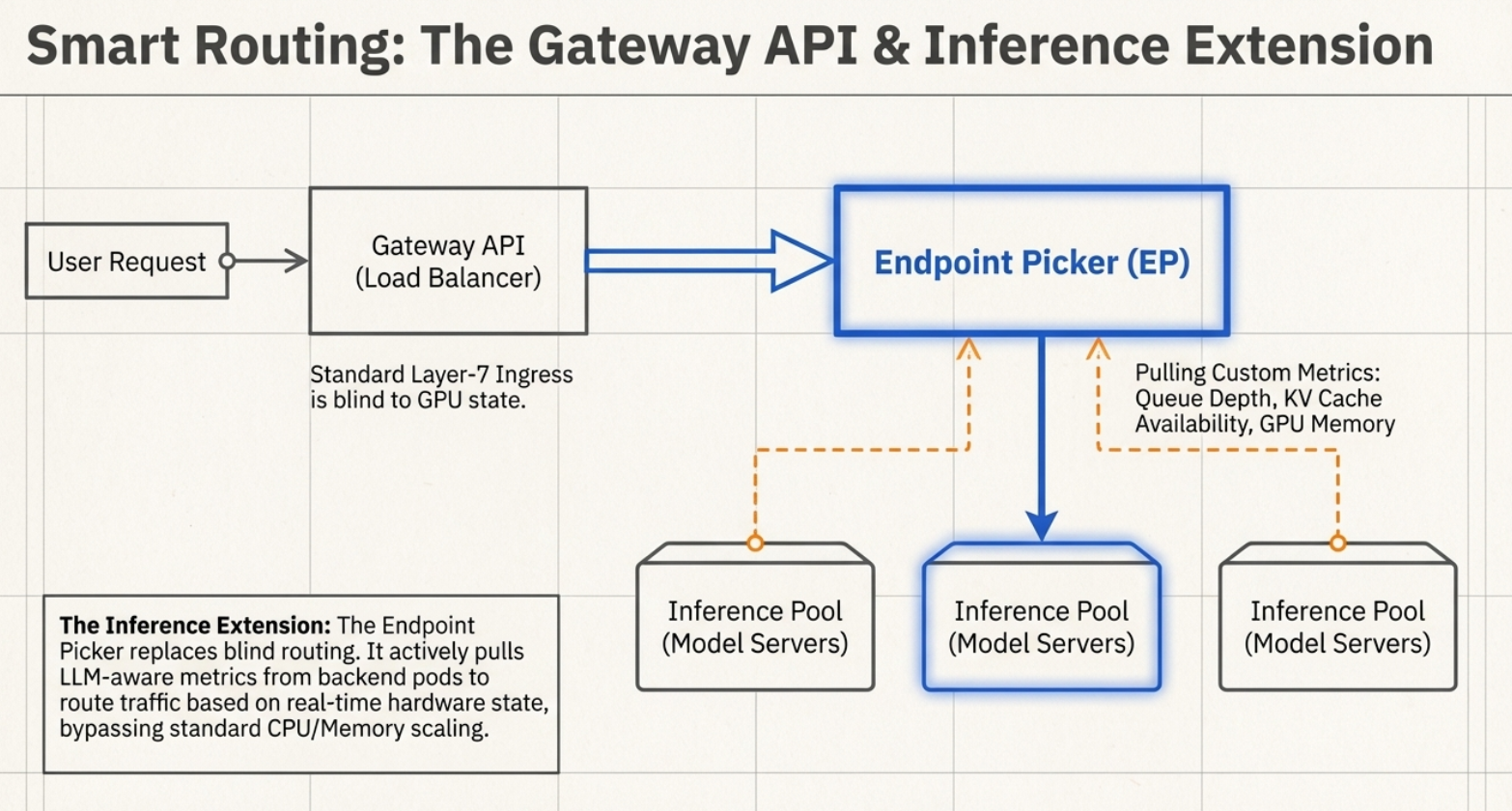
Endpoint Picker & Inference Extension: Model-aware routing that looks inside the request (Body-Based Routing) to find the specific Model ID and routes based on real-time KV cache utilization and queue depth.
Storage Optimization: Instead of "pulling" weights, nodes use FUSE (File System in User Space) to mount cloud storage buckets directly. This, combined with Image Pre-loading, allows a model to start "warming up" its GPU before the weights are even fully on the disk.
Conclusion: the Inference Stack in 2026
We have transitioned from a world of "simple hosting" to one of "intelligent distribution." The current inference stack is a sophisticated three-layer architecture: the Model (weights), the Engine (vLLM or SGLang), and the Orchestrator (LMD on Kubernetes).
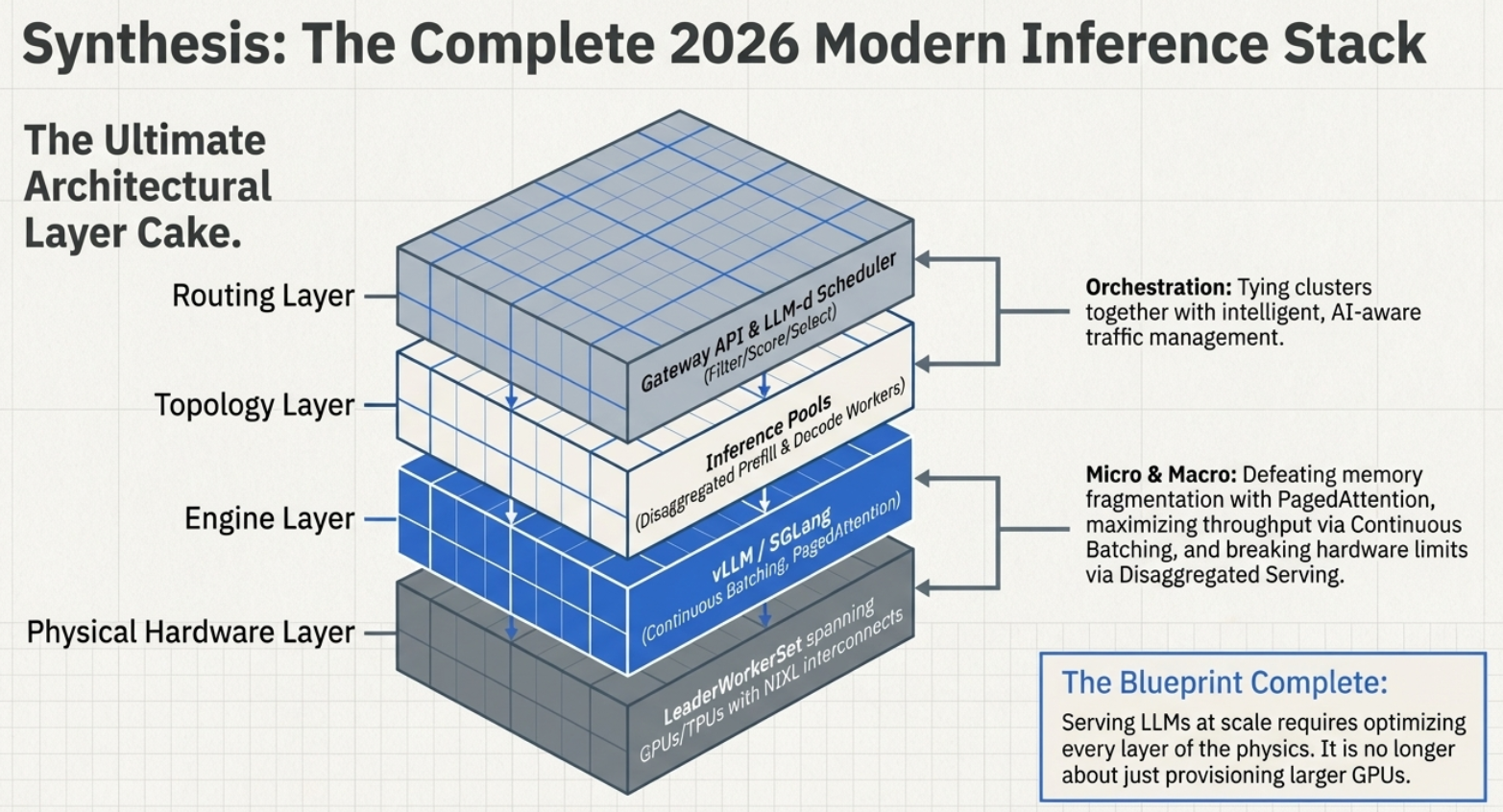
The goal is no longer just running a model; it is the surgical management of memory pages and the strategic splitting of math from bandwidth. As we audit our own infrastructure, we must ask: Are we still trying to scale the dynamic, memory-hungry reality of AI using the static web logic of a decade ago?